前言
对于CSS字体加密,我目前遇到了这几种情况:
- 字体字形坐标点与编码之间的对应关系不会随着多次请求而变化,例如:58同城房子出租
- 字体字形坐标点每次请求时,位置不固定,但是每个文字的打点数量一致,例如:猿人学第7题
- 字体的打点坐标点与打点数量随着每次请求都会发生变换,例如:58同城招聘
我们之所以认为1这个形状是数字一。是因为我们学习后,懂得,“哦!这个是 ‘1‘ 。”
所以,为了让电脑识别出文字,就可以依靠机器学习,啊,但是我不会。直接上手机器学习针对的是比较难识别的图像,例如:复杂的验证码。
对于有规则的字体,我们就可以借助OCR(光学字符识别)识别文字。
本文使用到就是**tesseract-ocr+简体中文训练集**
大致流程:
根据已有的字体文件,将这些字体绘制到图片上,再通过OCR识别这些字符。
注意:
- 字体越多,识别花费的时间就越长;
- 能通过字体文件规律解密的,则不建议使用这种方法;
环境配置
环境配置参考文章:https://blog.csdn.net/u010454030/article/details/80515501
下载tesseract
下载训练集
识别代码
# -*- coding: utf-8 -*-
"""
Created on 2021/4/27 16:34
---------
@summary:
---------
@author: mkdir700
@email: mkdir700@gmail.com
"""
import base64
import numpy
import pytesseract
from fontTools.ttLib import TTFont
from PIL import Image, ImageDraw, ImageFont
def fontConvert(fontPath):
"""
解析字体文件
:param fontPath: 字体文件路径
:return: 编码和汉字的对应关系
"""
font = TTFont(fontPath)
codeList = font.getGlyphOrder()[1:]
# print(codeList)
# 创建画布
im = Image.new("RGB", (1800, 1000), (255, 255, 255))
dr = ImageDraw.Draw(im)
# 加载字体文件对象
font = ImageFont.truetype(fontPath, 40)
word_count = len(codeList)
if word_count >= 40:
lines = word_count // 40 # 文字排列的行数,在图片上分行展示
else:
lines = word_count
arrayList = numpy.array_split(codeList, lines)
# print(arrayList)
# 将字体文件中的文字绘制成图片
for t in range(lines):
newList = [i.replace("uni", "\\u") for i in arrayList[t]]
text = "".join(newList)
text = text.encode('utf-8').decode('unicode_escape')
dr.text((0, 50 * t), text, font=font, fill="#000000")
im.save("temp.jpg")
# im = Image.open("temp.jpg") #可以将图片保存到本地,以便于手动打开图片查看
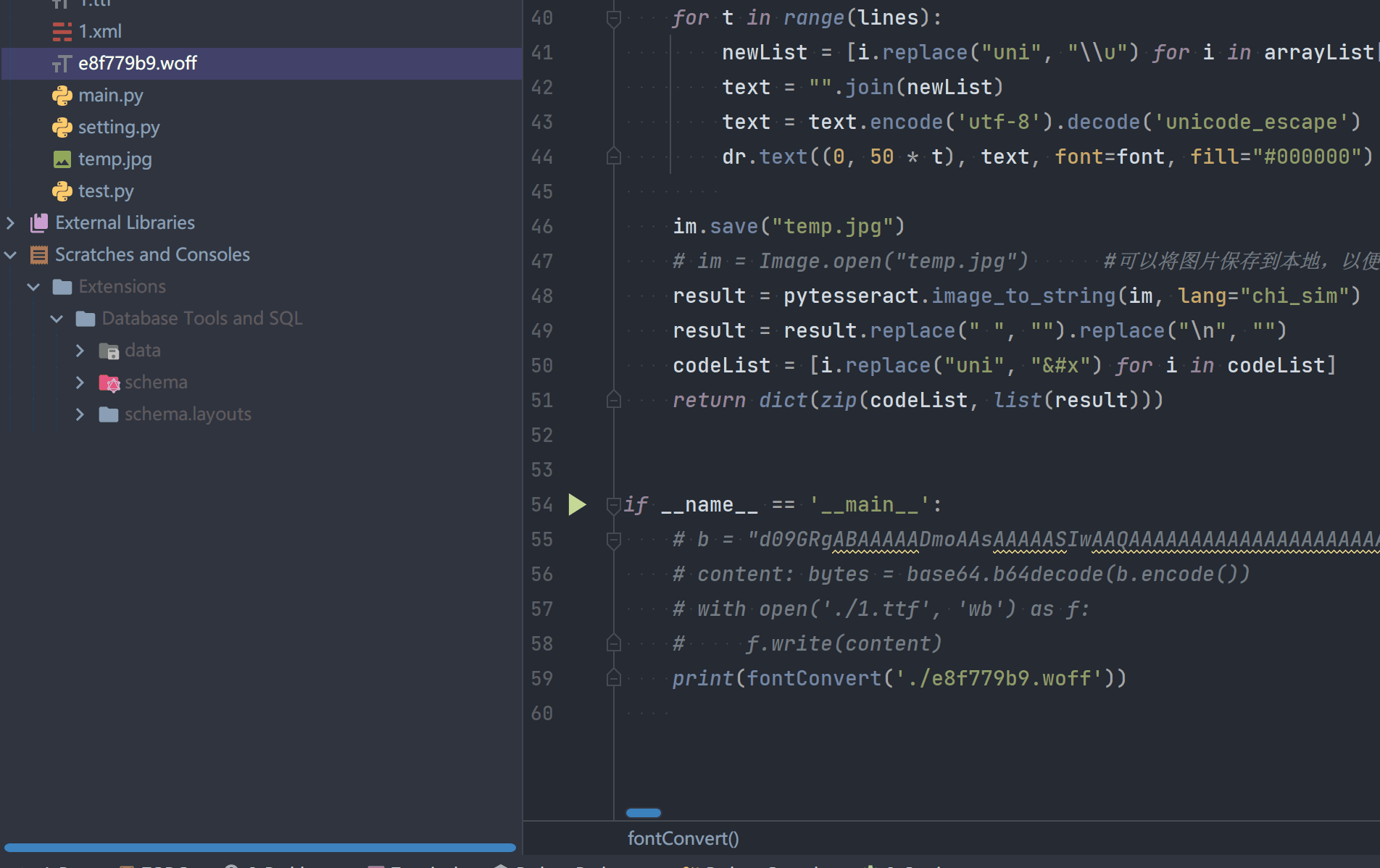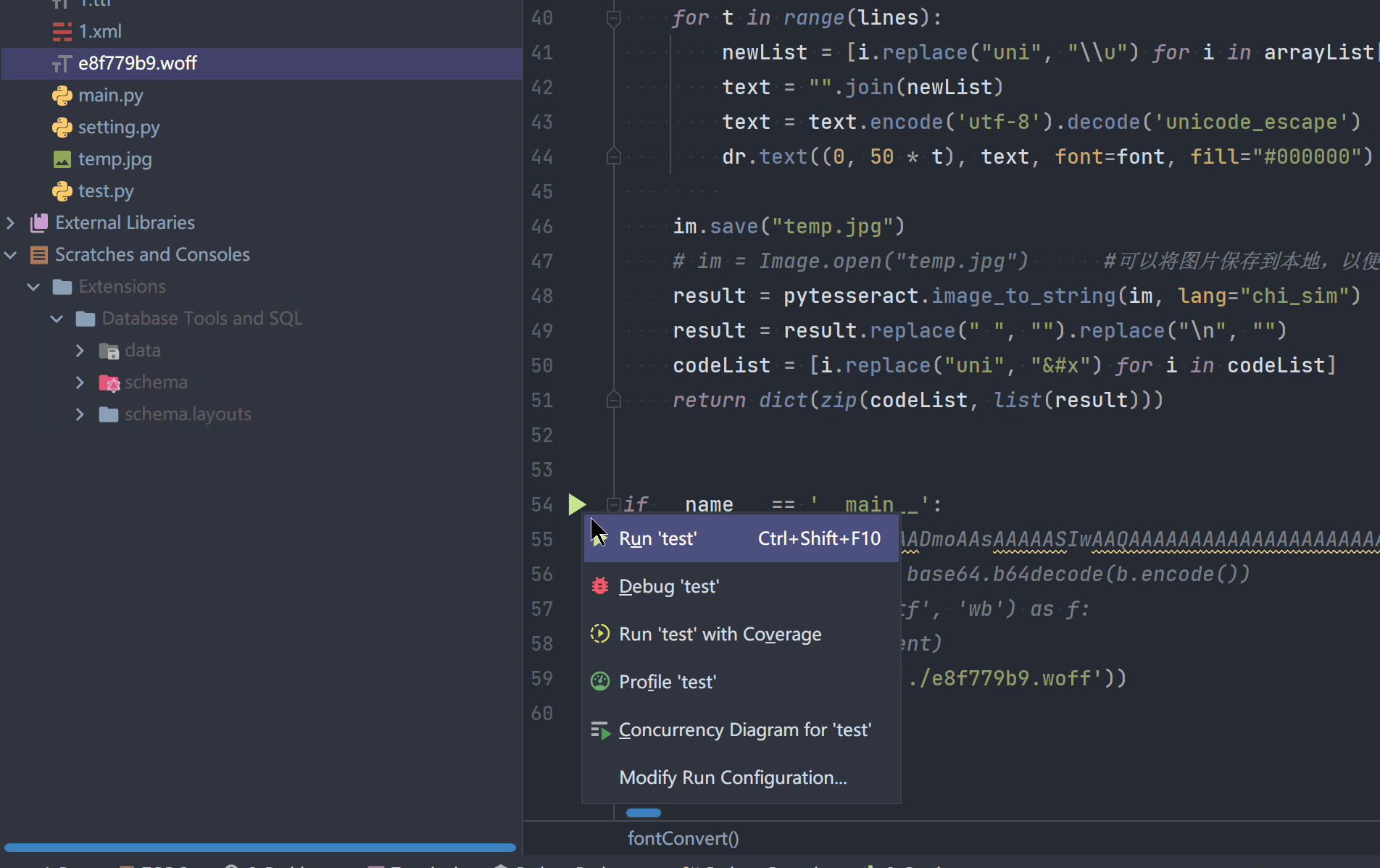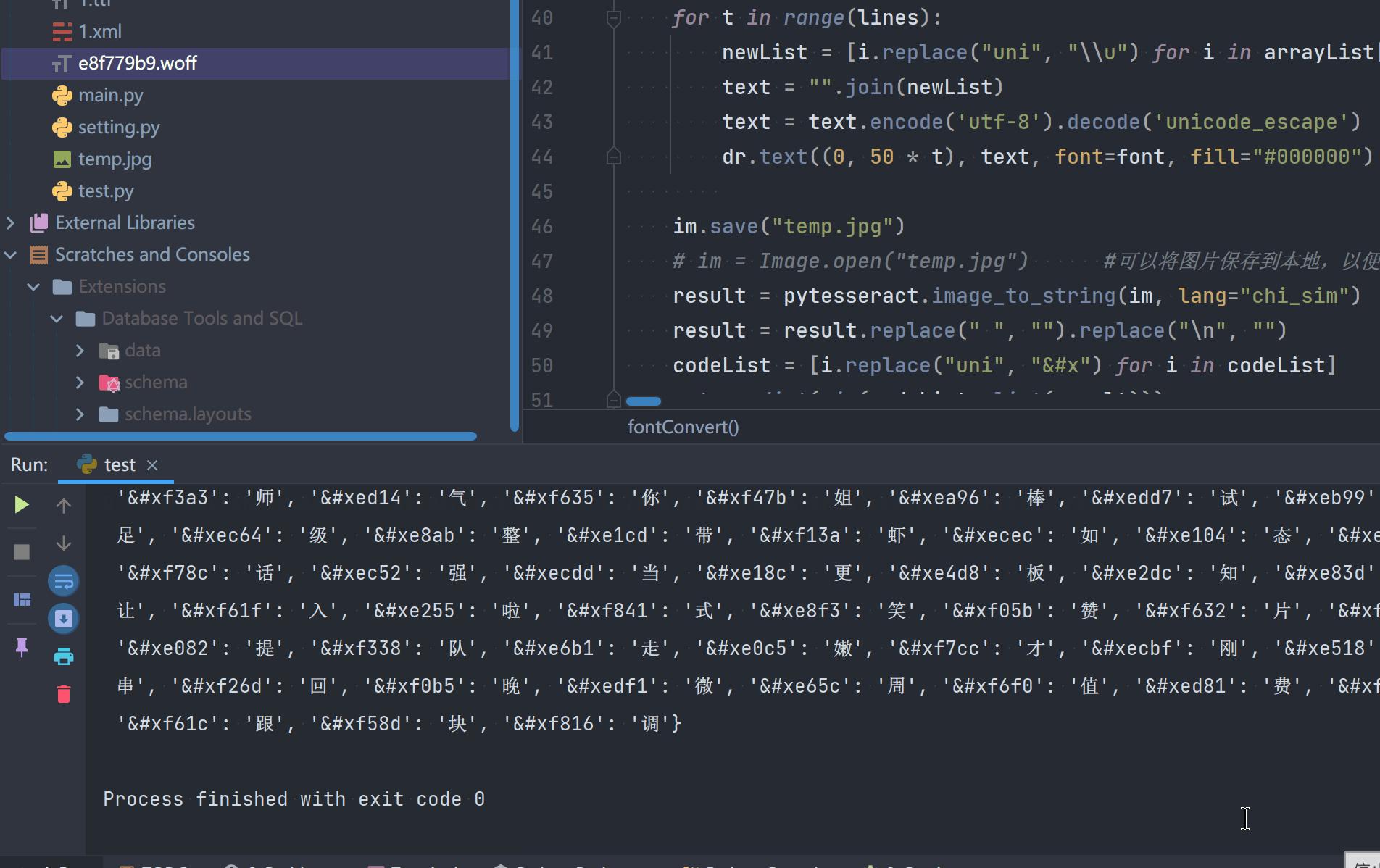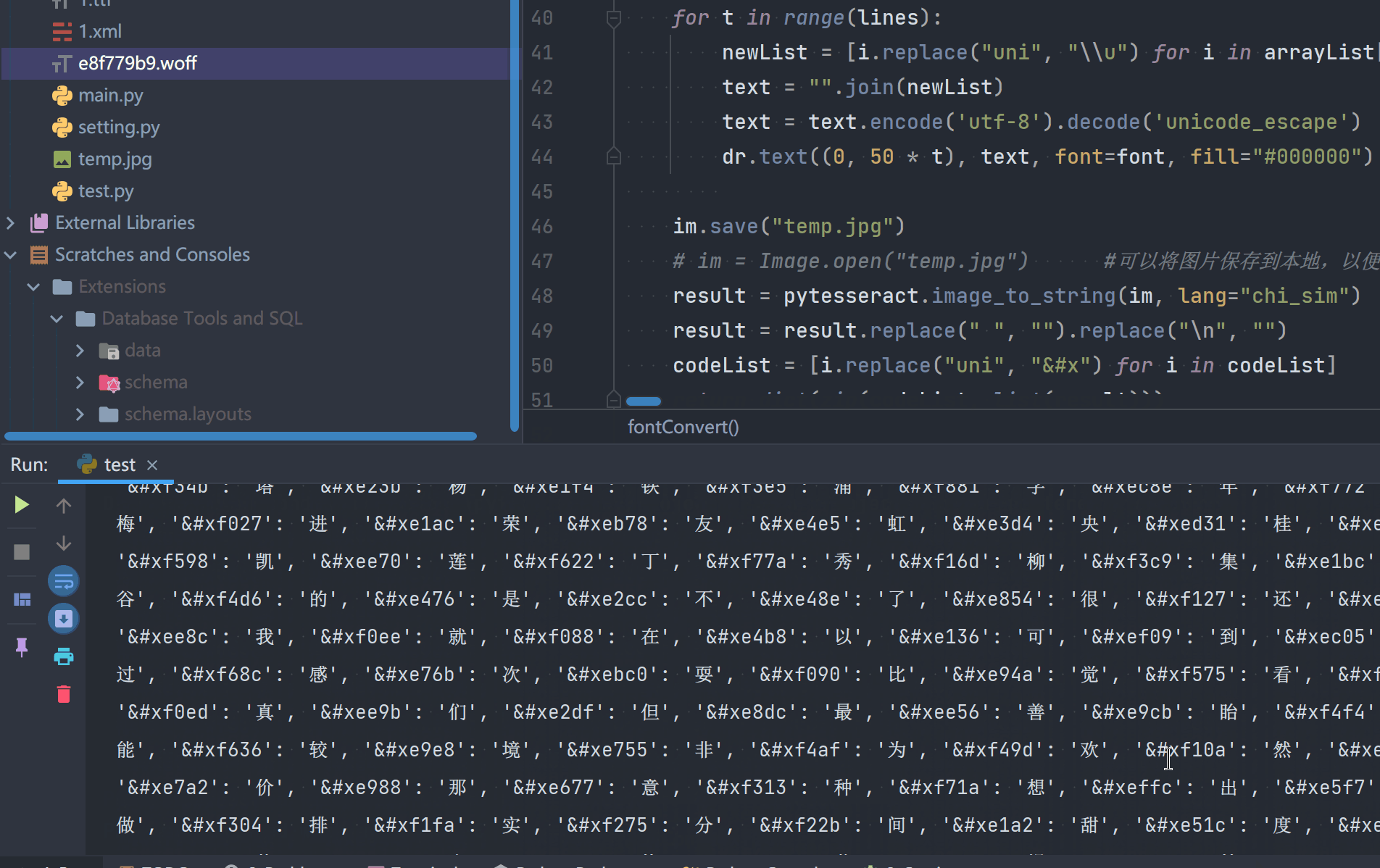
result = pytesseract.image_to_string(im, lang="chi_sim")
result = result.replace(" ", "").replace("\n", "")
codeList = [i.replace("uni", "&#x") for i in codeList]
return dict(zip(codeList, list(result)))
if __name__ == '__main__':
b = "xxxx="
content: bytes = base64.b64decode(b.encode())
with open('./1.ttf', 'wb') as f:
f.write(content)
print(fontConvert('./1.ttf'))
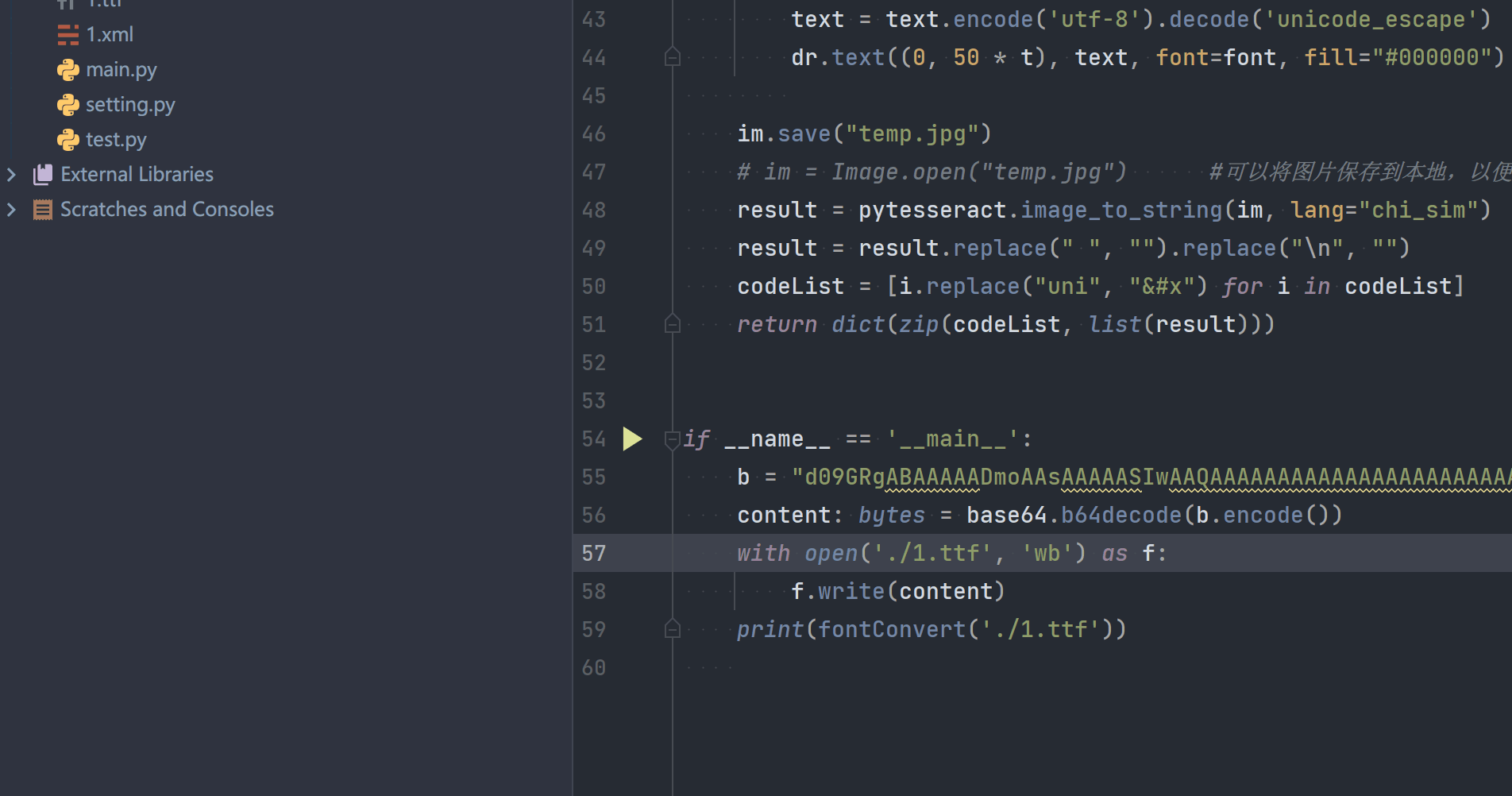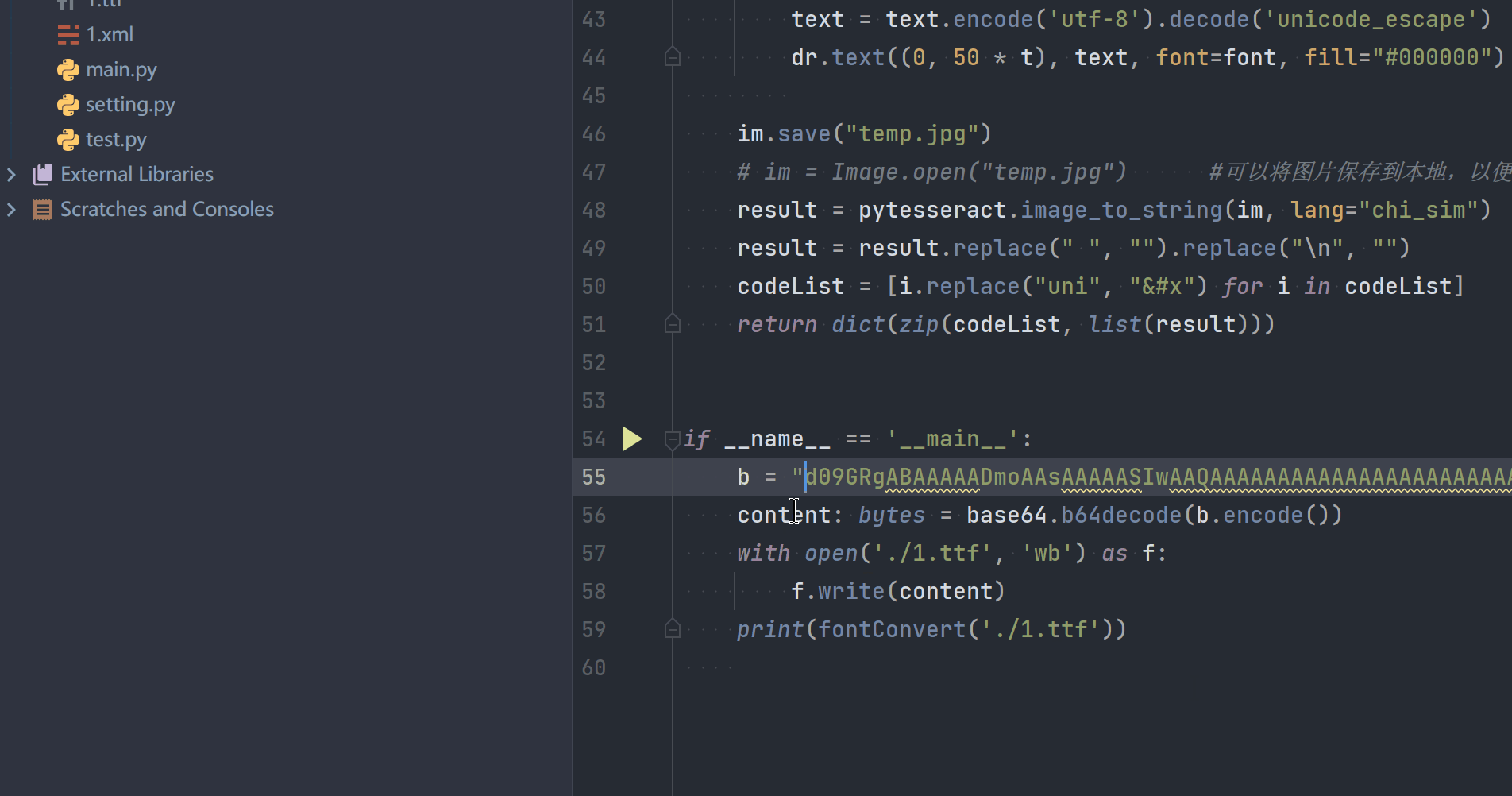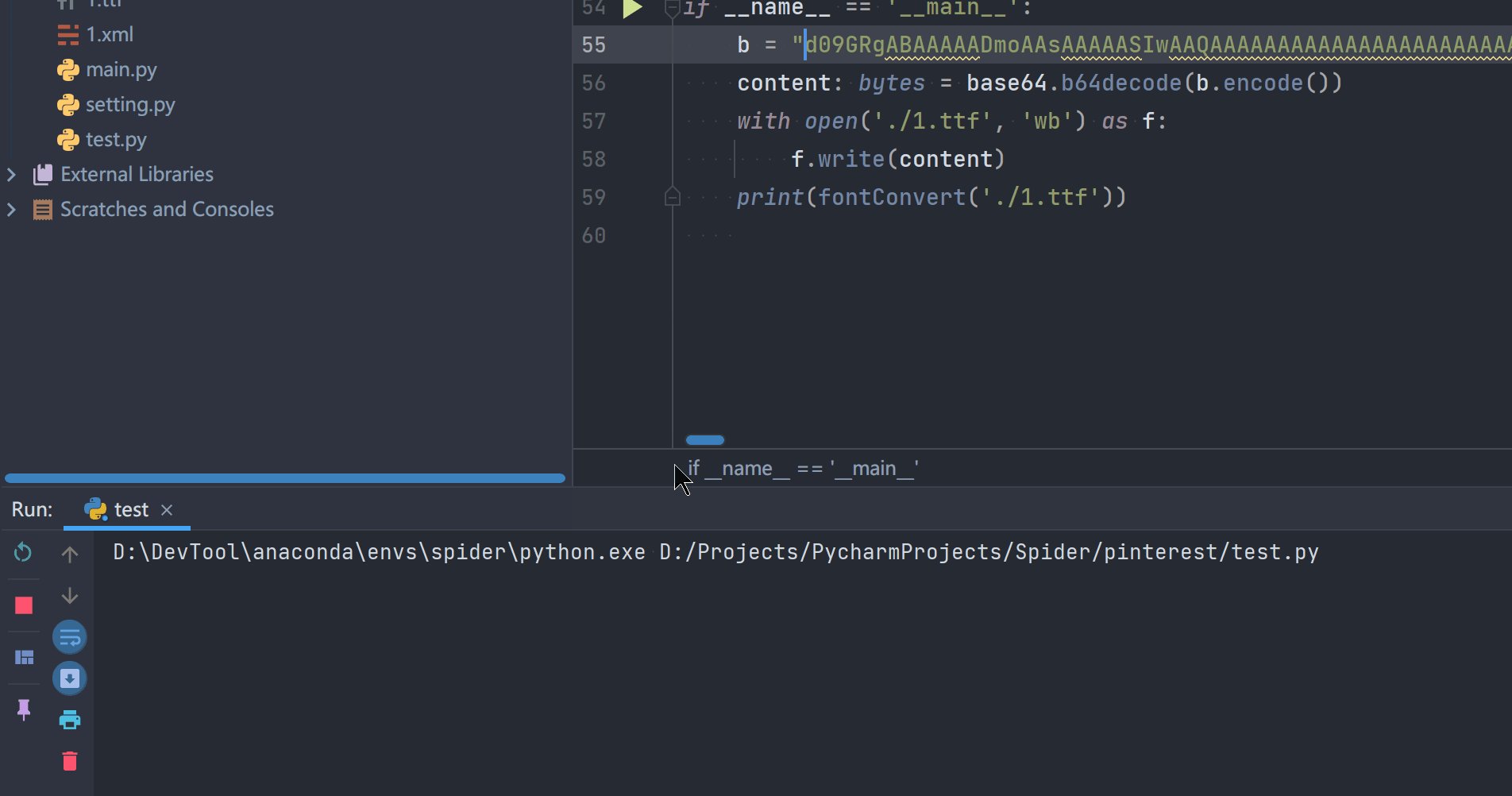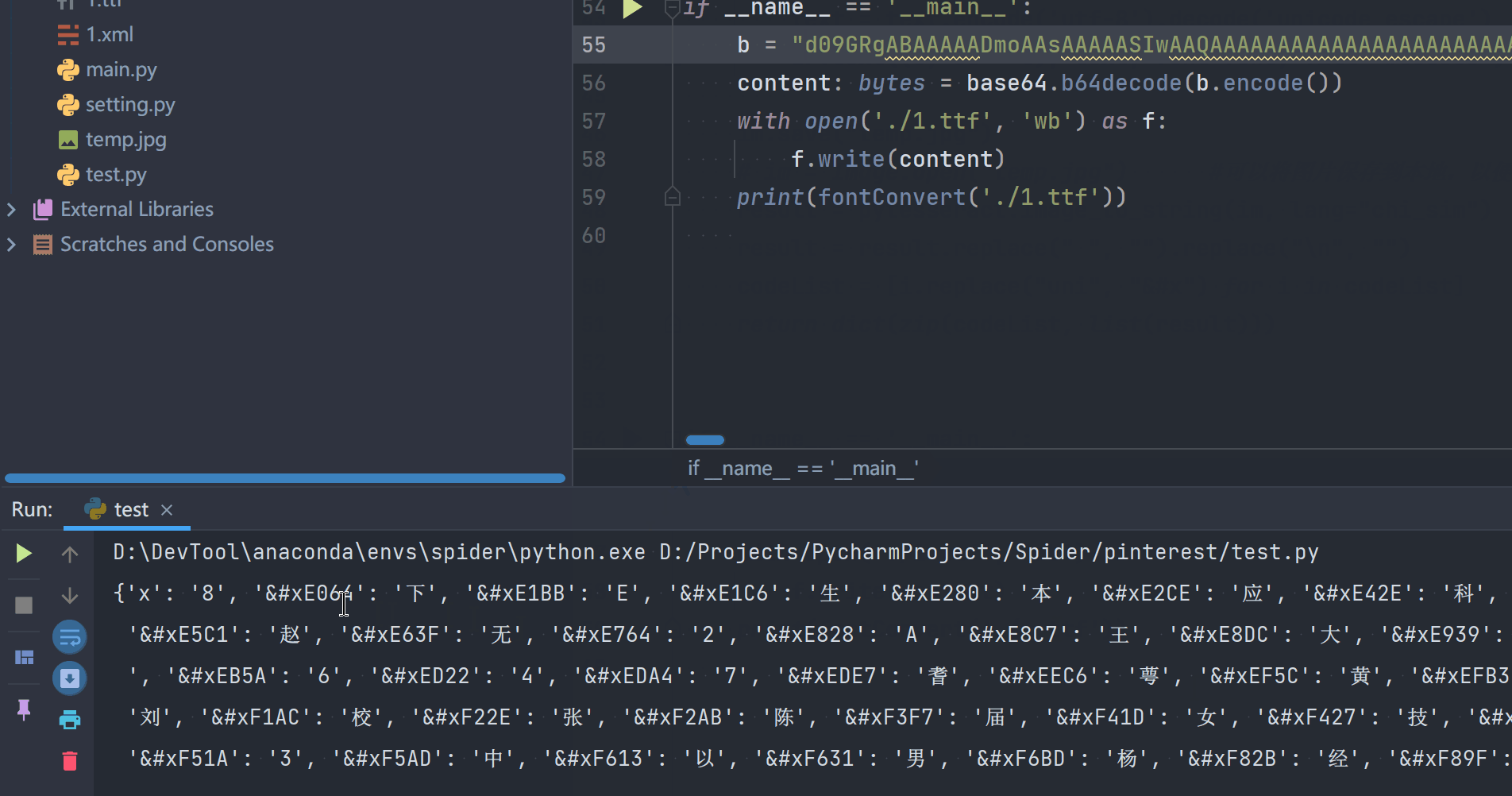
效果演示
站点:58同城
地址:https://bj.58.com/searchjob/
右键查看源代码可查看字体文件的base64编码
站点:大众点评
地址:http://www.dianping.com/shop/H7CLU1zL7C5X891z