静态多任务
造点假数据
from faker import Faker
import pymongo
faker = Faker(locale='zh_CN')
client = pymongo.MongoClient("mongodb://localhost:27018")
coll = client.get_database("test_db").get_collection("10w")
docs = [{"username": faker.language_name(), "age": faker.random_int(0, 100), "email": faker.email(), "ipv4": faker.ipv4()} for i in range(100000)]
coll.insert_many(docs)
编写DAG
从数据集合中读取10w条数据,再用一个任务去处理这些数据,假设每条数据的处理时间是0.0005秒。
import time
from datetime import datetime
from airflow import DAG
from airflow.models.taskinstance import TaskInstance
from airflow.operators.python import PythonOperator, task
from airflow.providers.mongo.sensors.mongo import MongoHook
default_args = {
'owner': 'airflow',
}
with DAG(
'test_static_mongo',
default_args=default_args,
description='connect MongoDB tutorial',
schedule_interval=None,
start_date=datetime(2021, 1, 1),
catchup=False,
tags=['test'],
) as dag:
def read():
# 读取指定的连接id,并与数据库建立连接
conn = MongoHook(conn_id="local_mongo")
# 获取集合(获得表),之后的使用就和Pymongo一模一样了
coll = conn.get_collection("10w", "test_db")
# 返回查询结果
docs = list(coll.find({}, {"_id": 0, "number": 1}))
return docs
def load(**kwargs):
ti: TaskInstance = kwargs.get("ti")
docs = ti.xcom_pull(task_ids="read_data_from_mongo")
for i in docs:
# 模拟数据处理耗时
time.sleep(0.0005)
read_task = PythonOperator(
task_id='read_data_from_mongo',
python_callable=read,
)
load_task = PythonOperator(
task_id="load_data",
python_callable=load,
)
read_task >> load_task
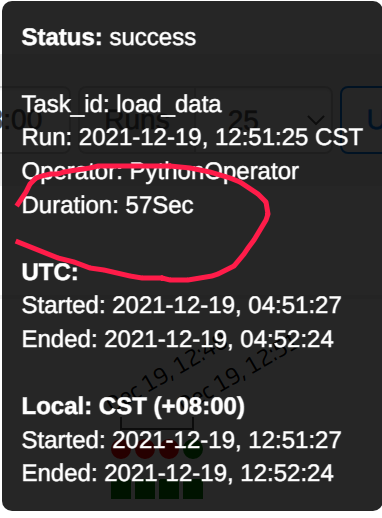
执行结果:
load_data 任务耗时57秒
改进DAG
对于这么多数据,我们不可能只开一个任务进行处理。当我们有多个任务同时去跑,是不是耗费的时间就大大减少了呢?
假设,我们启动10个load_data任务,每个任务需完成10000条数据的处理。
当数据从read_data中读出来的时候,我们需要对这批数据按每10000条数据为一组的规则进行分组,一共分10组。
我们可以遍历10次创建10个PythonOperator,并传入他们的索引值
load_tasks = []
for i in range(10):
op = PythonOperator(task_id="load_data_{}".format(i), python_callable=load, op_kwargs={'inx': i})
load_tasks.append(op)
在每个load_data任务内部,根据索引切片
inx = kwargs.get("inx")
for i in docs[inx * 10000:(inx + 1) * 10000]:
# 模拟数据处理耗时
time.sleep(0.0005)
修改后的代码:
import time
from datetime import datetime
from airflow import DAG
from airflow.models.taskinstance import TaskInstance
from airflow.operators.python import PythonOperator, task
from airflow.providers.mongo.sensors.mongo import MongoHook
default_args = {
'owner': 'airflow',
}
with DAG('test_static_mongo',
default_args=default_args,
description='connect MongoDB tutorial',
schedule_interval=None,
start_date=datetime(2021, 1, 1),
catchup=False,
tags=['test'],
concurrency=10) as dag:
def read():
# 读取指定的连接id,并与数据库建立连接
hook = MongoHook(conn_id="local_mongo")
conn = hook.get_conn()
# 获取集合(获得表),之后的使用就和Pymongo一模一样了
coll = hook.get_collection("10w", "test_db")
# 返回查询结果
docs = list(coll.find({}, {"_id": 0, "number": 1}))
conn.close()
return docs
def load(**kwargs):
ti: TaskInstance = kwargs.get("ti")
docs = ti.xcom_pull(task_ids="read_data_from_mongo")
# 根据索引值,切分
inx = kwargs.get("inx")
for i in docs[inx * 10000:(inx + 1) * 10000]:
# 模拟数据处理耗时
time.sleep(0.0005)
return inx
read_task = PythonOperator(
task_id='read_data_from_mongo',
python_callable=read,
)
load_tasks = []
for i in range(10):
op = PythonOperator(task_id="load_data_{}".format(i), python_callable=load, op_kwargs={'inx': i})
load_tasks.append(op)
read_task >> load_tasks
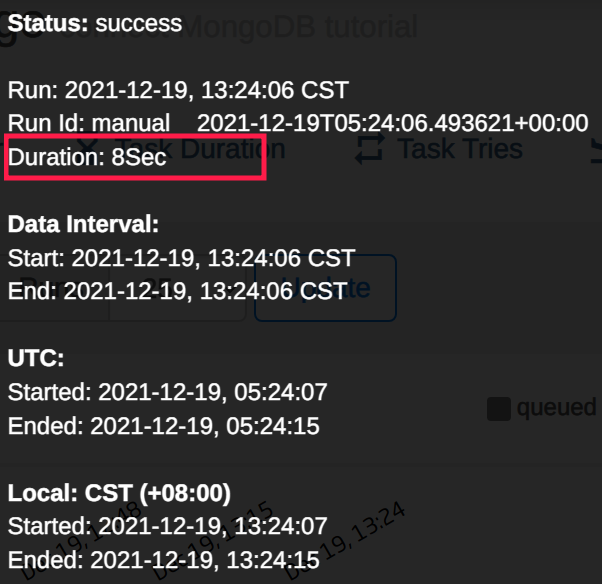
然后,就可以看到这样的结构

再次执行,总耗时8秒
动态多任务
在上一个例子中,提前设置了处理load_data 的任务数量以及每个任务处理的数据量。
在实际场景中,可能每次处理的数据量都不同,所以不能把代码写的这么“死”。
看作一个简单的乘法,需要处理的总数据量 =任务数量 × 和单个任务的数据处理量
我们固定一个变量,然后根据总数量动态调整另一个变量的值。例如:我规定单个任务处理的数据量是1000条,如果此时总数据量有10w条,那就动态生成1000个任务同时去跑。
Airflow在调度时,是会去执行DAG文件的,所以我们只需要在DAG中动态遍历生成Task即可。
原理就是,在开始执行任务前,先去数据库把数据读出来,然后再动态分配任务,所以read不再作为一个任务去执行,而是看作一个普通函数,将函数返回值分片后分配给后续任务。
完整代码:
import time
from datetime import datetime
from airflow import DAG
from airflow.models.taskinstance import TaskInstance
from airflow.operators.python import PythonOperator
from airflow.providers.mongo.sensors.mongo import MongoHook
default_args = {
'owner': 'airflow',
}
with DAG('test_daynamic_mongo',
default_args=default_args,
description='connect MongoDB tutorial',
schedule_interval=None,
start_date=datetime(2021, 1, 1),
catchup=False,
tags=['test'],
concurrency=10) as dag:
def read():
# 读取指定的连接id,并与数据库建立连接
hook = MongoHook(conn_id="local_mongo")
conn = hook.get_conn()
# 获取集合(获得表),之后的使用就和Pymongo一模一样了
coll = hook.get_collection("10w", "test_db")
# 返回查询结果
docs = list(coll.find({}, {"_id": 0}))
conn.close()
return docs
def load(**kwargs):
# 根据索引值,切分
docs = kwargs.get("docs")
for i in docs:
# 模拟数据处理耗时
time.sleep(0.0005)
return docs
docs = read()
for i in range(0, len(docs), 1000):
op = PythonOperator(task_id="load_data_{}".format(i),
python_callable=load,
op_kwargs={'docs': docs[i * 1000:(i + 1) * 1000]})
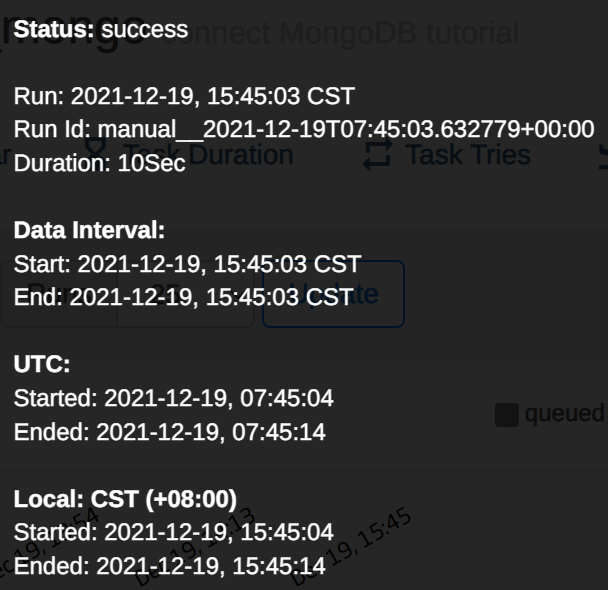
生成后的图:

执行耗时30s

疑惑了?和预期不符,任务量比之前大得多,为什么执行时间还变长了这么多呢?
原因:
- 对于每个DAG都有最大任务并发量的限制,这可以在创建DAG时配置
- 对于Airflow后端数据库而言,也有连接数的限制。
sqlalchemy.exc.OperationalError: (psycopg2.OperationalError) FATAL: sorry, too many clients already
所以,我也不能一味的去增加任务数量,当把单个任务处理量修改至4000时,就正常了许多。
小结一下:
- 根据数据量动态生成任务数;
- 不能一味追求任务量;
下篇文章我将总结,【入门Airflow】 实战ETL任务: 从Mongo到Mysql。