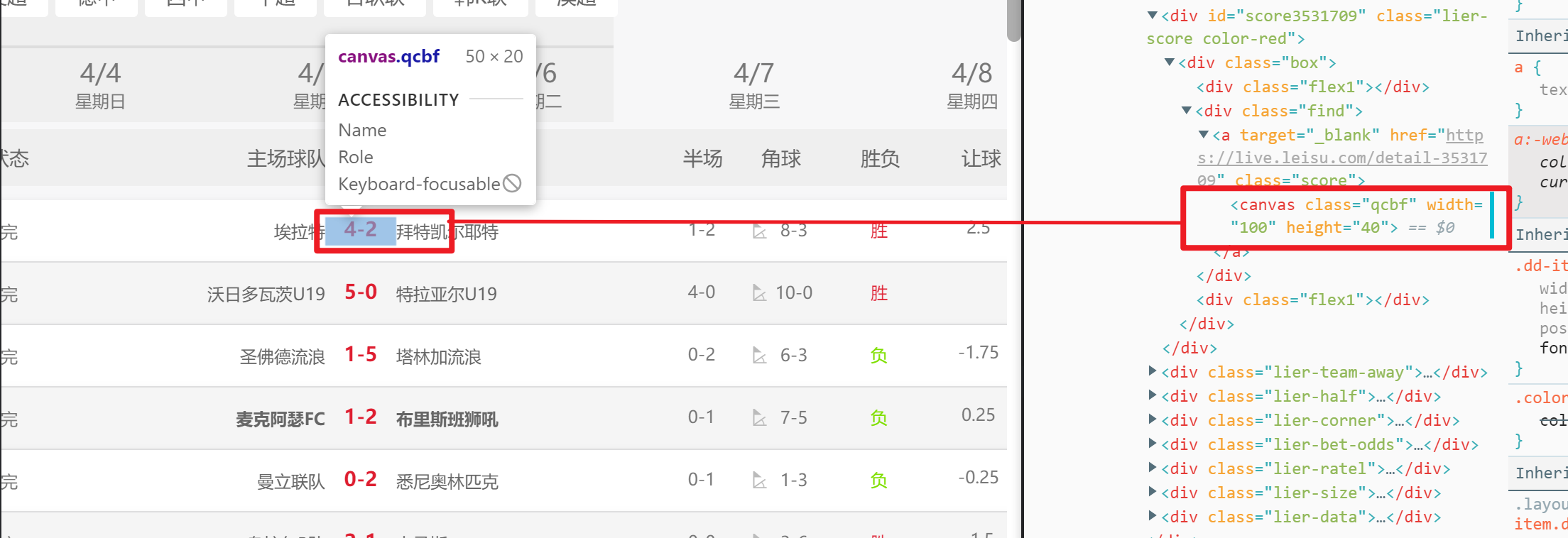
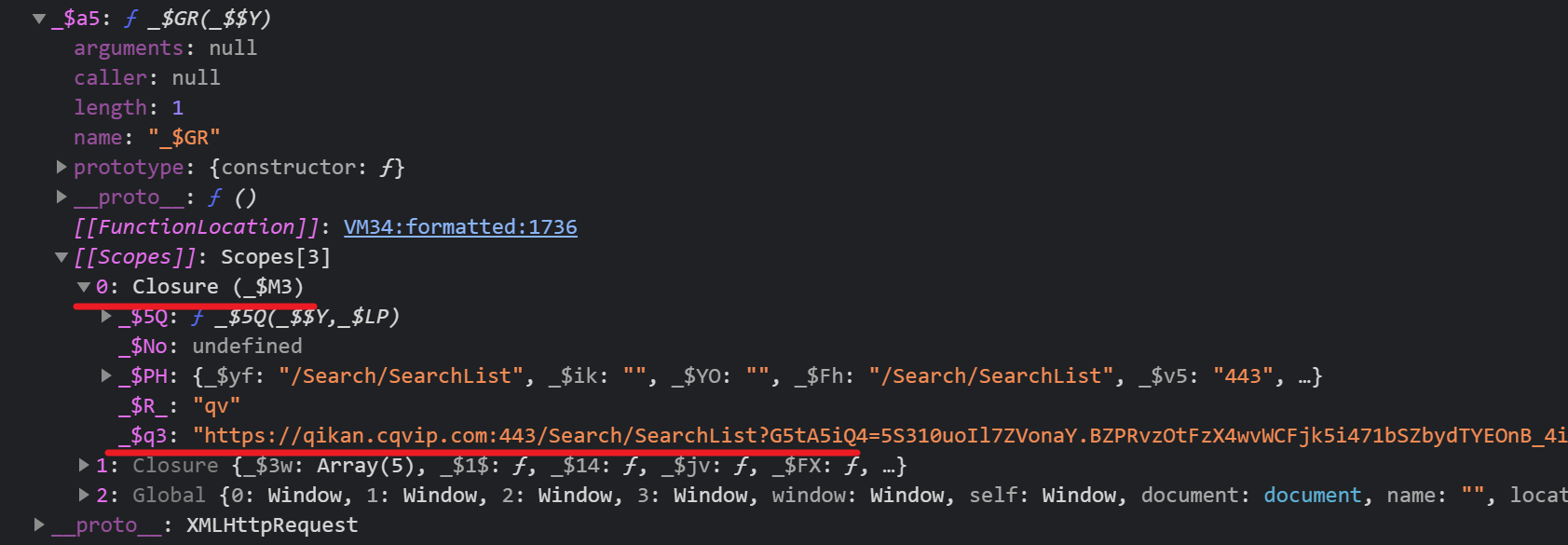
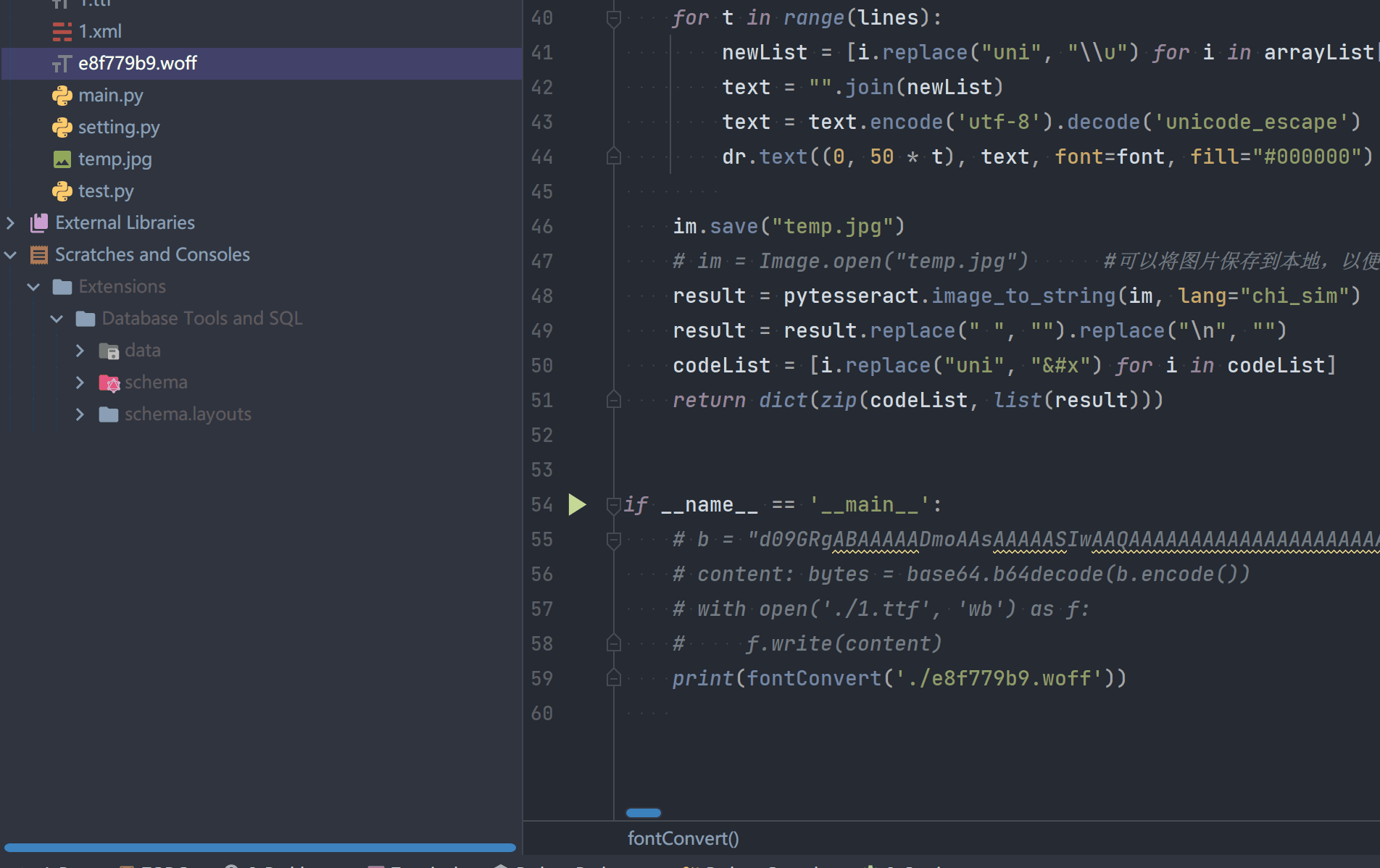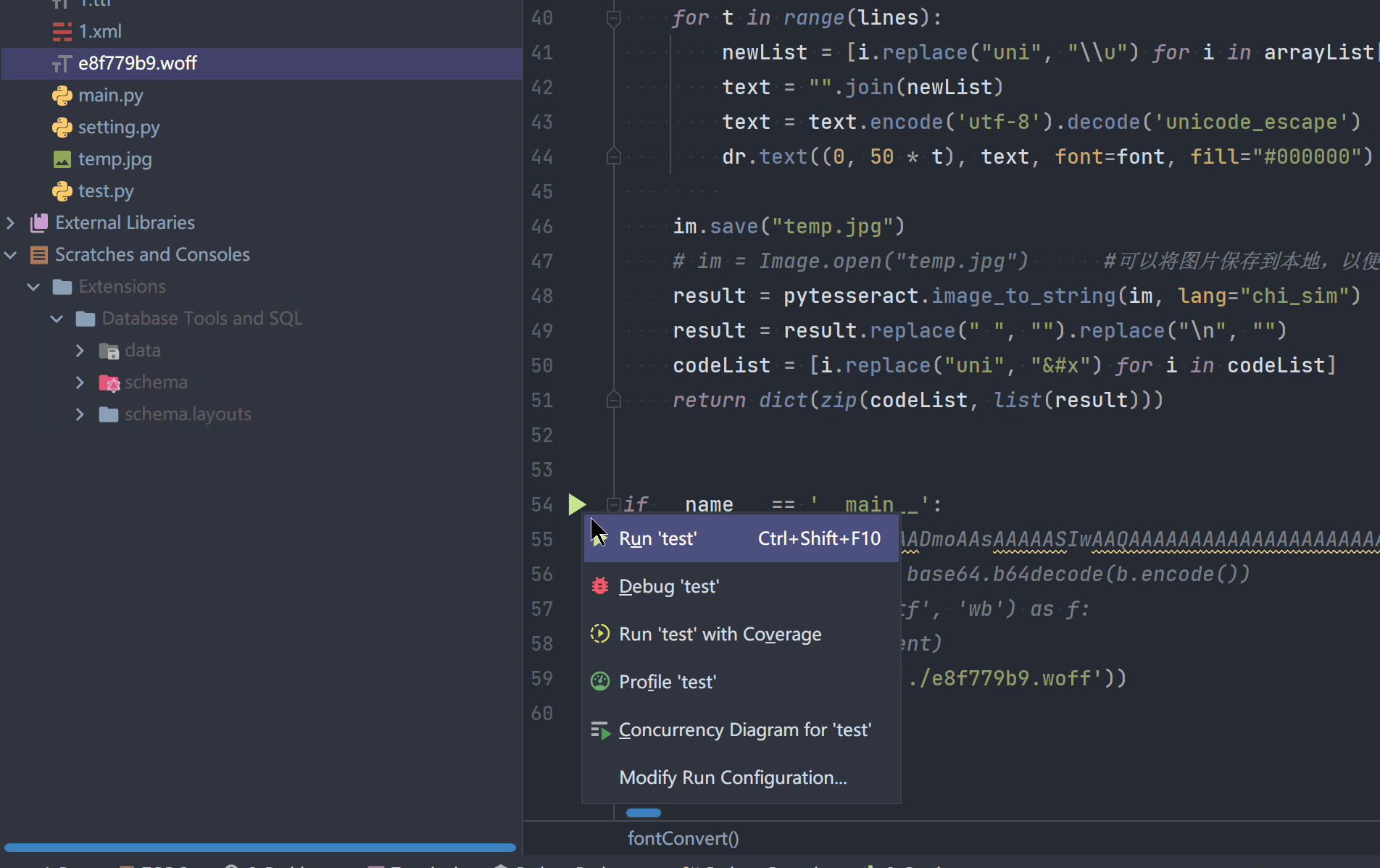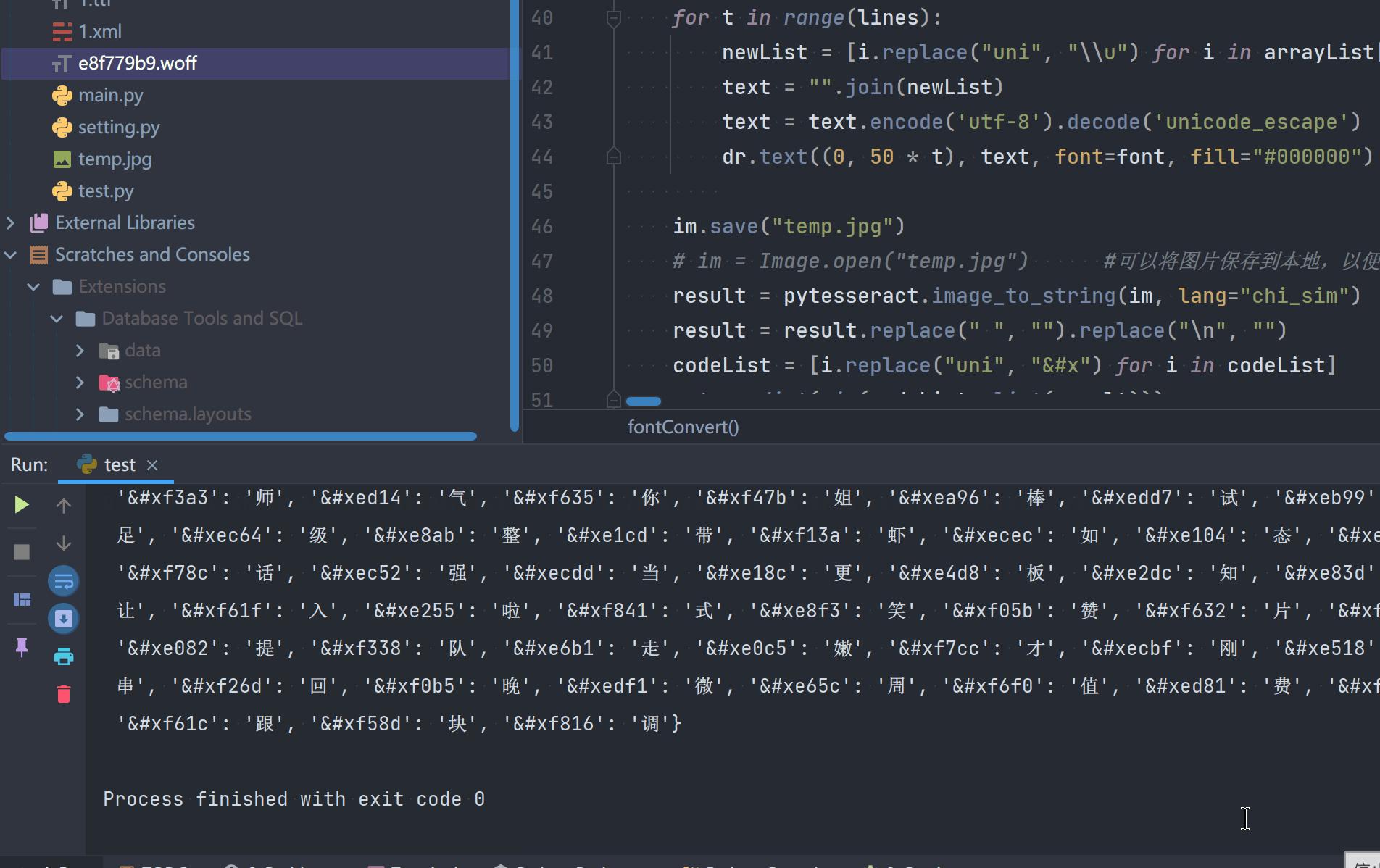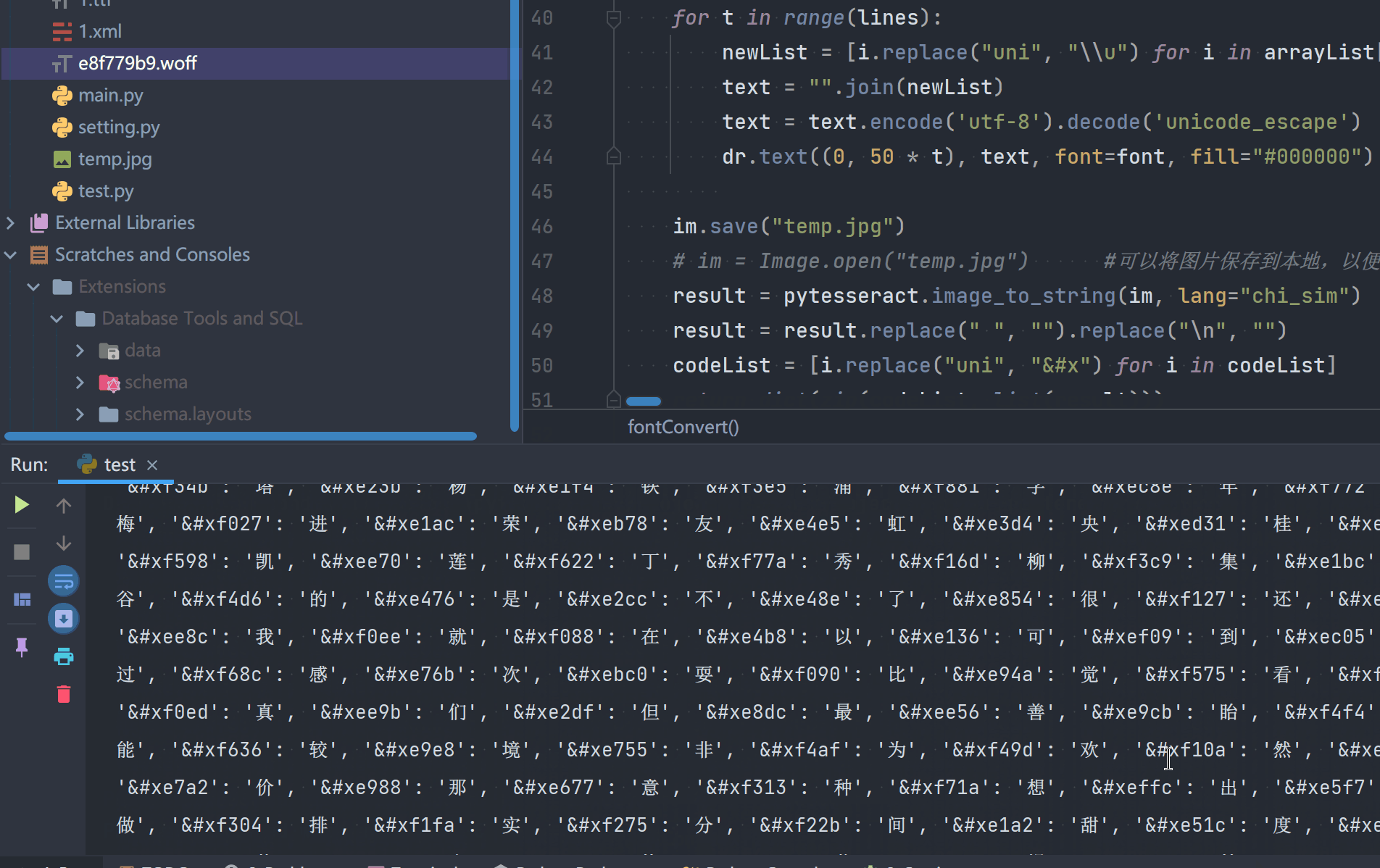
【瑞数】维普期刊搜索接口逆向总结_2_获取Cookie
一提到cookie的获取,第一想法就是简单。通常的流程就是请求一下网页,然后在响应中提取cookie即可。 但是在维普期刊这个例子里,并不是这样。先来了解在调试中我所遇到的实际问题。 然后在后文中,我们一一来解决这些问题。
一提到cookie的获取,第一想法就是简单。通常的流程就是请求一下网页,然后在响应中提取cookie即可。 但是在维普期刊这个例子里,并不是这样。先来了解在调试中我所遇到的实际问题。 然后在后文中,我们一一来解决这些问题。
前言使用protobuf主要是两个步骤,序列化和反序列化。关于Proto有哪些数据类型,然后如何编写,此处就不赘述了,百度一下有很多。此文主要是总结,python使用protobuf的过程,如何序列化和反序列化,对不同类型的字段如何进行赋值。序列化下面将一一列举各数据类型,在python中如何正确赋
前言本文意在记录,在爬虫过程中,我首次遇到Protobuf时的一系列问题和解决问题的思路。文章编写遵循当时工作的思路,优点:非常详细,缺点:文字冗长,描述不准确protobuf用在前后端传输,在一定程度节约了带宽,也为爬虫工程师增加了工作量。遇见Protobuf一拿到网站,F12查看是否有相关数据的